


 メルマガ登録
メルマガ登録
















マーケティングは、どこまで人間を理解できるのか #18
バイロン・シャープの「ブランド論」を最新脳科学の仮説から検証してみる

前回のおさらいと今回のねらい
早いもので、連載再開からもう1ヵ月です。まずは次の写真を使って、前回のおさらいから始めましょう。

あるスーパーマーケットの棚の一部に加工を加えたものです。かなりぼかしていますが、写っているのが缶飲料であることはもちろん、これらがエナジードリンクであることや、ブランドや具体的なバリエーションまで分かる人もいるでしょう。
私たちの脳に入ってくる感覚情報は、この写真のように制約だらけです。たとえば、視覚ならば、周辺視野がぼやけていたり、自身の動きによってブレブレだったり、重要な部分が陰になって欠けていたりします。それにもかかわらず、安定した知覚世界を築けるのは、すでに持っている脳の内部モデルを使って常に外界を予測し、それとの誤差で外の世界を推測しているからだ、というのが前回ご紹介した仮説でした。
今回は、この予測誤差に基づく「知覚の計算原理」を概観したあと、消費者のアクションや行動にも同じ枠組みを適用し、最後にその応用としてブランディングに関連付けていきます。
予測符号化理論の計算原理
予測符号化理論では、脳内での現実世界の推論を、ベイズ推定の原理によって説明します。下の図(脚注1)を使って概観しましょう。
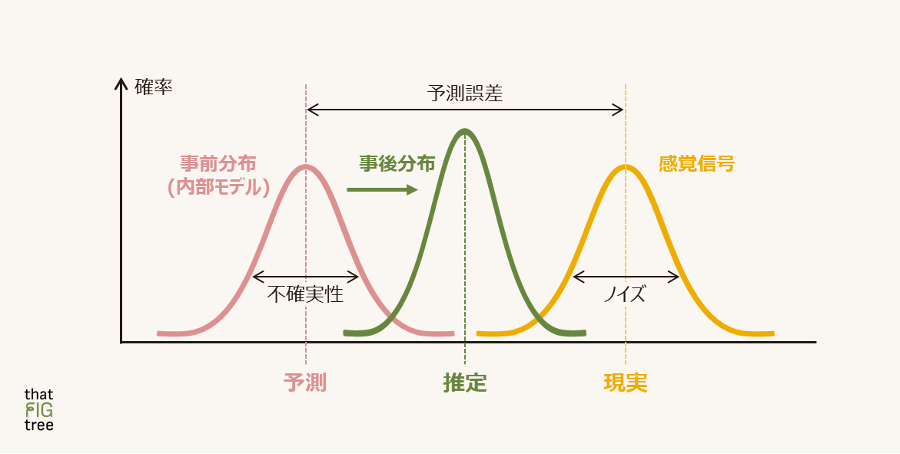
外界から入ってくるであろう情報の「予測」(あらかじめ持っている内部モデルに基づくもの)が、左のピンク色の「確率分布」として表現されています。予測には常に不確実性が伴うため、分布の真ん中あたりである確率がもっとも高く、もう少しずれている可能性もありそうです。ただ、分布の端っこのほうである確率は、それほど高くはないだろうと、予測されているのです。これが、ベイズの「事前分布(prior distribution)」にあたります。
一方で、感覚信号として入ってくる「現実」の情報も、確率分布となっています(右の黄色の分布です)。冒頭でお話しした通り、入力されてくる情報にはノイズが含まれていて、現実そのものが脳に届くわけではないためです。これが「尤度(likelihood)」にあたり、これをもとにベイズの定理で事後分布(中央の緑色の分布です)が計算され、予測が更新されることで内部モデルが精緻化されます(脚注2)。
少し難しかったかもしれませんが、ここでお伝えしたかったのは、あらかじめ仮説を立てておき、実際に観測された値に基づいて、より確からしい仮説へ更新するようなイメージです。この枠組みの中では、知覚は、脳内で生成した「予測」(内部モデル)と実際の感覚入力の誤差に基づいて、現在の外界の状態を推定することとされ、この一連の過程は特に「知覚的推論」(perceptual inference)と呼ばれます。モデルを更新し最新に保つということを繰り返すことで、刻々と変化する外界を知覚し続けることが可能になるというわけです。
ここで、知覚経験に影響する重要な要因として、予測や感覚入力の精度が挙げられます。たとえば、過去に何度も経験した事象では、内部モデルの精度が高く、逆に初めて遭遇するようなものは、モデルの精度が低いと考えられます。同様に、外界から入ってくる感覚情報も、たとえば、明るくて周囲に邪魔な刺激が少ない場合や、何らかの理由でそこに注意を集中している場合などは、精度が高まるでしょう。
予測符号化の枠組みでは、このような情報の精度は、確率分布の分散、つまり図の中の分布の幅で表現されます。具体的に、図を次のように少し調整してみましょう。
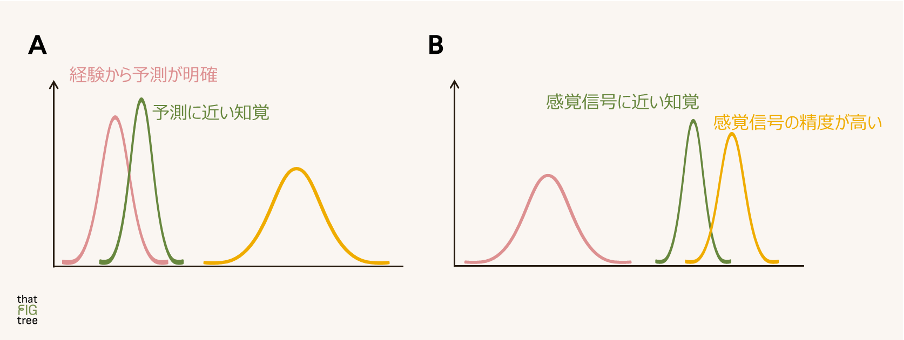
この図のAのほうでは、ピンクの分布の幅が小さいので、予測の精度が高く、一方で感覚信号(黄色)の精度は低いことを示しています。このような場合、経験される知覚は予測に依存し、内部モデルに近いものとなります。
具体例として、冒頭のスーパーの棚の写真のような場合が挙げられます。画像がぼやけていて感覚信号の精度は高くはありませんが、よく知っているカテゴリーやブランドなので精度の高い内部モデルが存在し、(知らず知らずのうちに)それによって知覚できていると想定されます。
図のBはその逆で、経験される知覚は入力されてくる感覚信号に近くなっています。あまりよく知らない場面に遭遇して、対象を注意深く観察している場合などが該当するでしょう。
予測符号化理論によれば、このベイズ推定のような計算が、視覚だけでなく聴覚や触覚などすべての感覚モダリティにおける知覚処理で、脳内の低次のレベルから高次中枢まで階層的になされていると考えられています(脚注3)。